SRCNN
Das Ziel dieses Projekts ist es, die Qualität von Bildern mit niedriger Auflösung zu verbessern und zu erhöhen.
1- SRCNN Model
In SRCNN ist die Netzwerkstruktur tatsächlich einfach. Zuerst wird ein Bild mit niedriger Auflösung als Eingabe verwendet, und nach Faltungen wird es zu einem Bild mit hoher Auflösung wiederhergestellt.
Es gibt drei Faltungsschichten: Patch-Extraktion und -Darstellung, nichtlineare Abbildung und Rekonstruktion, wie in der folgenden Abbildung dargestellt:
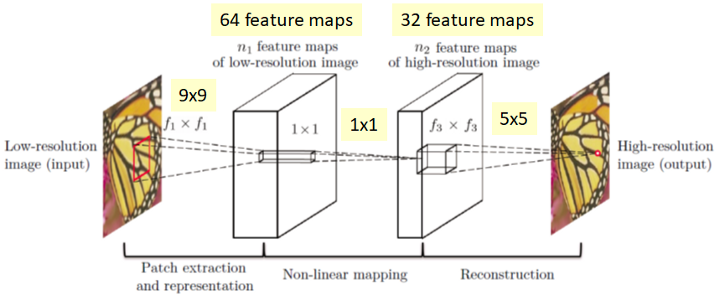
In unserem Code haben wir 64 output filters und eine Kernelgröße von 9x9 in der ersten Faltungsschicht bzw. Patch-Extraktion. Die zweite Faltungsschit hat 32 output filters und eine kernelgröße von 1x1 und für die letzte Faltungsschit eine output filter und eine Kernelgröße von 5x5. In der forward()-Funktion wenden wir die ReLU-Aktivierung nur auf die erste und zweite Faltungsschicht an.

2- Reading the Training Data and Preparing the Training and Validation Set

Wir werden die train.h5 in Training und Validierung aufteilen. Unsere Sub-images sind 33*33 groß und die sind alle in grayscale format, d.h. die Anzahl von kanälen ist 1.
Die Datei train.h5 enthält insgesamt zu viele sub-images. Die in_train und out_train enthalten die Trainigsbilddaten und Trainingsbildlabels. Wir werden auch die Daten in Training und Validierung aufteilen
3- Preparing the Dataset

- Labels sind Bilder mit hoher Auflösung.
- Input data sind Bilder mit niedriger Auflösung.
In der Funktion getitem() geben wir sowohl die inputs-data als auch die labels als PyTorch-Float-Tensoren zurück, da es sich bei beiden um Bilder handelt.
Bevor wir die Training und Validierung data loaders definieren, brauchen wir das Trainings- und Validierungsdataset zu initialisieren.
4- Verlustfunktion & PSNR
PSNR ist der wichtigste Teil, denn dadurch soll die Ähnlichkeit von den Bildern gemessen werden.
Je höher der PSNR-Wert, desto besser.
Obwohl PSNR die Schätzung der Bildqualität bereitstellt, benötigen wir dennoch etwas, um die Verbesserung unseres neuronalen Netzwerks zu verfolgen. Wir werden dies über die MSE-Verlustfunktion tun.

Die Funktion PSNR() übernimmt zwei Parameter. Das erste ist label aus dem SRCNNDataset() und das zweite sind die Outputs, die wir aus dem SRCNN-Model erhalten. Der Parameter max_val ist der maximale Wert des Pixels in unseren Daten. Da wir alle Pixel in unseren Daten zwischen 0 und 1 haben, ist max_val daher auch 1.
In der MSE() Funktion, haben wir das Label und die Outputs auf die CPU geladen und sie dann in NumPy-Vektoren konvertiert. Wir müssen dies tun, bevor wir mathematische und NumPy-Operationen an den Werten durchführen.
5- Training Data

-
Wir definieren running_loss und running_psnr, um den batch-wise loss und die PSNR-Werte zu verfolgen.
-
Wir setzen den Optimizer auf Null, backpropagation die Gardienten und aktualisieren die Parameter.
-
Wir erhalten den Wert von batch_psnr, indem wir die Funktion PSNR() aufrufen. Dann fügen wir die batch_psnr zur running_psnr hinzu.
5- Validation Data

Die Funktion validate() akzeptiert einen zusätzlichen Epochenparameter. Wir werden dies verwenden, um die sub-images nach jeder Epoche zu speichern. Daraus können wir erkennen, ob die sub-images wirklich hochauflösend sind oder nicht.
6- Ausführen von train() und validate() Funktionien

-
Wir werden das SRCNN-Modell für 100 Epochen trainieren und validieren
-
Wir haben vier Listen im obigen Codeblock. Die train_loss, val_loss speichern die Verlustwerte nach jeder Epoche, und die train_psnr und val_psnr speichern die PSNR-Werte nach jeder Epoche.
Hier ist ein kleines Beispiel aus unseren Ergebnissen:
Epoch-size 1:

Epoch-size 100:

7- Speichern der grafischen Darstellungen und des Models
Jetzt müssen wir nur noch die grafischen Darstellungen für die Verlust- und PSNR-Werte speichern, damit wir sie später analysieren können. Wir speichern auch die Model weights auf der Festplatte. Auf diese Weise können wir sie laden und das Modell einfach mit unseren Testdaten testen.

Testbilder als Eingabe für Training

-
Aufrufen von allen Testbildern und Erstellung einer For-loop, um auf jedes Bild von Testbildern zuzugreifen.
-
Die Pixelwerte durch 255 teilen, sodass alle Werte jetzt zwischen 0 und 1 liegen.
-
Umwandeln von Image in Channel-first mit image = np.transpose(image, (2, 0, 1)).astype(np.float32) und dann in torch tensor umwandeln.
-
Speichern und Visualisierung von Ergebnissen.
Ergebnise von SRCNN Model
Am Ende des Trainings erhalten wir eine größe Erhöhung der Trainings-PSNR-Wert von 23,951 bis auf 28,757 dB.

| LR-Image | HR-Image |
 |
 |
 |
 |
 |
 |