Assignment H: PySpark (10 Pts)
Apache Spark is an open-source unified analytics engine for large-scale data processing. Spark provides an interface for programming clusters with:
-
implicit data parallelism and
-
fault tolerance.
Challenges
- Challenge 1: Get PySpark Containers - (3 Pts)
- Challenge 2: Set-up simple PySpark Program - (2 Pts)
- Challenge 3: Run on PySpark Cluster - (3 Pts)
- Challenge 4: Explain the Program - (2 Pts)
1.) Challenge 1: Get PySpark Containers
Setup PySpark as Spark Standalone Cluster with Docker:
https://github.com/cluster-apps-on-docker/spark-standalone-cluster-on-docker
The setup looks like this:
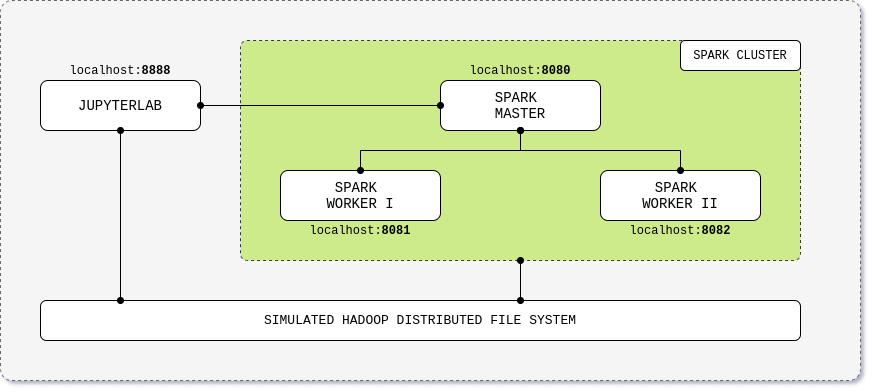
One simple command will:
-
fetch all needed Docker images (~1.5GB).
-
create containers for: Spark-Master, 2 Worker-Processes, Jupyter-Server.
-
lauch all containers at once.
Clone the project and use as project directory:
git clone https://github.com/cluster-apps-on-docker/spark-standalone-cluster-on-dockerFetch images, create and launch all containers with one command:
docker-compose upIt will launch the following containers:
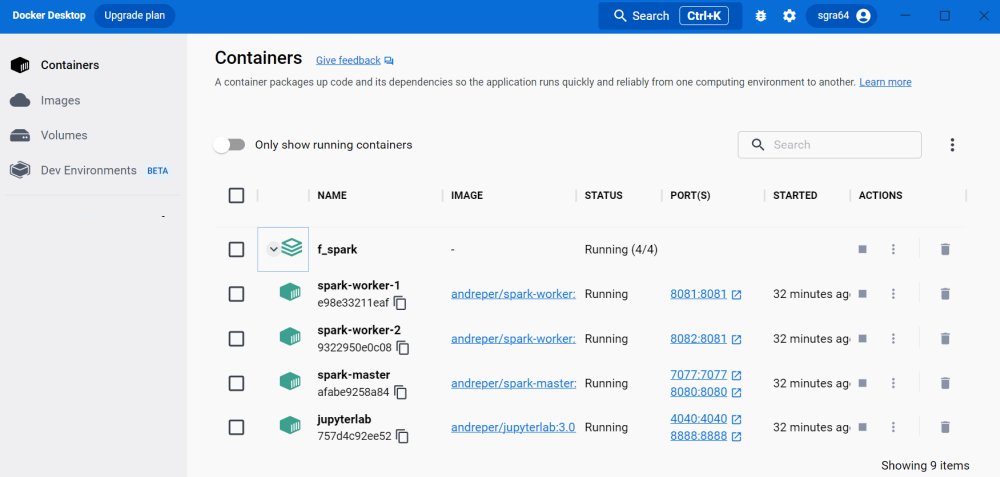
Open Urls:
| Application | URL | Description |
|---|---|---|
| JupyterLab | localhost:8888 | Cluster interface with built-in Jupyter notebooks |
| Spark Driver | localhost:4040 | Spark Driver web ui |
| Spark Master | localhost:8080 | Spark Master node |
| Spark Worker I | localhost:8081 | Spark Worker node with 1 core and 512m of memory (default) |
| Spark Worker II | localhost:8082 | Spark Worker node with 1 core and 512m of memory (default) |
2.) Challenge 2: Set-up simple PySpark Program
Understand the simple PySpark program pyspark_pi.py:
from __future__ import print_function
import sys
from random import random
from operator import add
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("PyPi").getOrCreate()
slices = 1
n = 100000 * slices
def f(_):
x = random() * 2 -1
y = random() * 2 - 1
return 1 if x ** 2 + y ** 2 <= 1 else 0
count = spark.sparkContext.parallelize(range(1,n+1), slices).map(f).reduce(add)
print("Pi is roughly %f" % (4.0 * count / n))
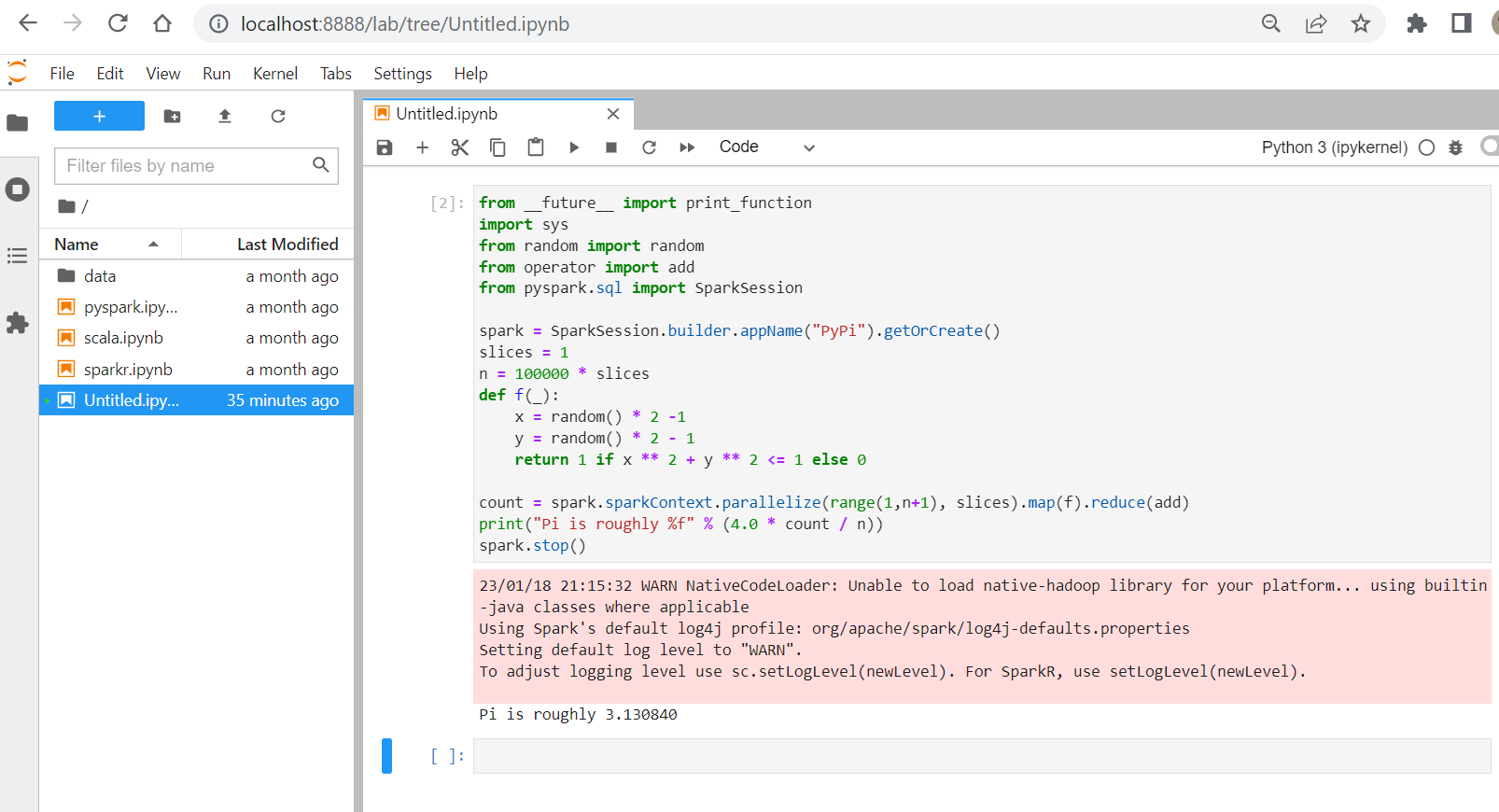
spark.stop()What is the output of the program?
What happens when the value of variable ‘slices’ increases from 1 to 2 and 4?
3.) Challenge 3: Run on PySpark Cluster
Open Jupyter, http://localhost:8888 and paste the code into the cell.
Execute the cell.
4.) Challenge 4: Explain the PySpark Environment
Briefly describe which essential parts a PySpark-environment consists of and concepts:
-
RDD, DF, DS
-
Transformation
-
Action
-
Lineage
-
Partition